Products
From modular data centers to high-performance racks and cloud orchestration, Polymor builds the infrastructure for AI to thrive everywhere.
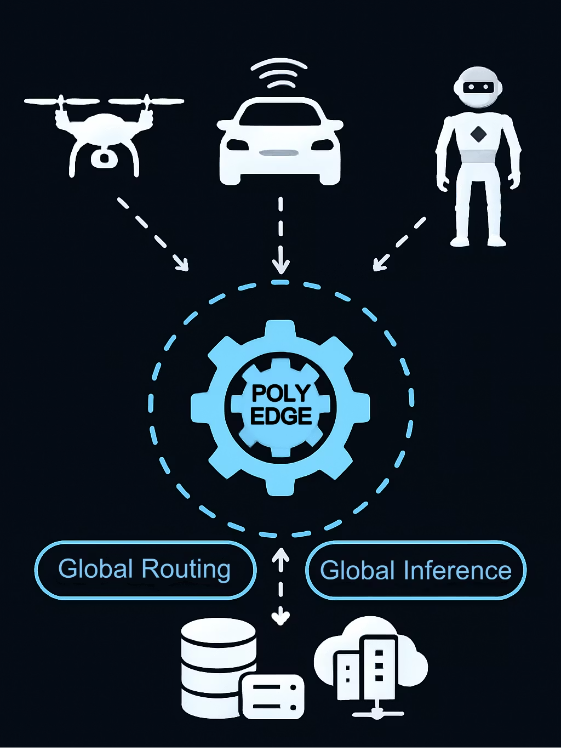
PolyEdge™
Powering the Next Generation of Autonomous and agentic systems
Core Features
Seamless Model Hosting
Deploy and manage AI models at optimal edge locations
Universal Inference Access
Standardized endpoints for frictionless AI integration
Intelligent Request Routing
Dynamic load balancing for optimal performance
Real-time Data Streaming
Persistent connections for continuous intelligence
Ultra-low Latency Results
Immediate delivery of inference outputs
Global Routing & Inference Network
Our distributed network intelligently orchestrates AI workloads across global edge locations, ensuring optimal performance, reliability, and cost-efficiency.
- Distributed edge compute network
- Smart request routing and load balancing
- Real-time data processing and streaming
- Ultra-low latency inference delivery

Polypod
Our design philosophy focuses on modularity, AI optimization, and compatibility with all major AI chips.
.png)
Polypod™
Ultra High Density AI Optimized Data Center Pod
Supports 6-8 high-density 47U racks per container
60-140kW per rack, with 4x NVIDIA H200 or similar AI servers
Liquid cooling (Direct-to-Chip or Cold Plate)
N+1 or 2N redundant power and cooling infrastructure
AI-ready and easily deployable

Optimized for AI Usage
High Density
Purpose-built for AI workloads with ultra-high density configurations supporting the latest AI accelerators.
Efficient Cooling
Advanced liquid cooling systems designed specifically for the thermal demands of AI hardware.
Rapid Deployment
Prefabricated, modular design allows for quick installation and scaling to meet growing AI compute demands.
Polyrack
Purpose-built racks to power AI inference workloads with maximum efficiency and density.

Advanced Cooling Technology
Our liquid cooling solutions are designed to handle the extreme heat generated by dense AI workloads, maintaining optimal operating temperatures while drastically reducing energy consumption.
Vendor Agnostic Design
Our racks are designed to work with all major AI accelerators, giving you the flexibility to choose the hardware that best suits your specific workloads and requirements.
Key Features
- •
32–64 GPUs per rack
- •
Supports Nvidia H800, H20, H100, A100, H200 and Huawei Ascend 910B/C
- •
Fully liquid cooled, 60–140kW per rack
- •
Chip and vendor agnostic
- •
PUE as low as 1.06
- •
Developed in collaboration with AI hardware partners